

Mislim da je došlo vrijeme da objedinimo znanje koje smo do sad stekli i izložimo se onome što nas čeka u budućnosti. Recimo da smo dobili zadatak na seminaru, ili planiramo preko ljeta raditi kao konobar da bismo uštedili novac da kupimo SPSS umjesto Excela, i zanima nas koliko ćemo napojnice (manče, bakšiša) dobiti obzirom na npr. spol.
Hajmo po redu i pokušat ću ne-skretati izvan sadržaja prošlih blogova. Imamo dvije opcije ispred sebe na početku, odabir eksperimentalnog ili korelacijskog istraživanja (vi koji ste slušali predmete istraživačkih metoda, možda primjećujete da sam preskočio jedan izbor koji se događa i prije ovoga a taj je kvalitativno ili kvantitativno istraživanje, dobro ste primjetili, carry on). Ukoliko bih se odlučio za eksperimentalno istraživanje što bih napravio? Imam nekoliko opcija, npr. mogu određenim stolovima slati muške konobare a određenim stolovima ženske konobare. Mogu u jednom restoranu imati samo ženske konobare a u drugom restoranu samo muške. Naravno, pritom moram paziti da su restorani
- podjednako dobri,
- skupi,
- veliki,
- popunjeni,
- uređeni, naravno i paziti da
- podjednak broj ljudi sjedi za stolovima,
- da imaju podjednako velike račune i
- da podjednak broj muškaraca i žena ti konobari poslužuju
- itd. itd itd.
Ne djeluje mi pre-realno da bih u takav neki pothvat ušao čisto da dam primjer kako provesti istraživanje. Alternativa je korelacijsko istraživanje. Dakle, na kraju smjene dođem do konobara (njih 244 da budem precizan) i saznam podatke koje mi mogu dati (npr. zabilježim njihov spol, za sad). Koja je razlika, možete me pitati, između ovog načina i eksperimentalnog?? Pa razlika je što nismo imali uvid niti smo kontrolirali koliko (i koje) ljude je koji konobar/ica posluživao. Stoga je moguće da su konobarice češće posluživale muške goste a muški konobari ženske goste što je dovelo do razlike u količini manče ali ne kao posljedica spola konobara već kao posljedica spola gosta. Isto tako, nismo pratili doba dana u kojem su konobari operirali taj dan, nismo bilježili u kojem restoranu su radili (možda, malo vjerojatno ali moguće, da su u "boljim" restoranima konobari svi žene te stoga razliku u manči opisujemo kao posljedicu razlike u kvaliteti restorana a ne u spolu konobara). Ako ste pratili do sad, podsjetili smo se preduvjeta za eksperimentalno istraživanje - eliminacija alternativnih plauzibilnih objašnjenja koje u ovom našem slučaju nije zadovoljeno...
Osim spola, što bi još, ovako napamet, moglo utjecati na količinu manče koju konobar zaradi? Da je ovo znanstveni problem, ovo napamet nam ne bi prošlo, morali bismo dobro iščitati literaturu na tu temu i iz nalaza prethodnih istraživanja pokušati predvidjeti što bi sve moglo biti povezano s većom mančom. Recimo da sam istražio literaturu (jer nas je profesor tlačio da moramo imati i znanstvene članke u seminaru *bljuv*) i saznao da su povezani ukupna visina računa i manča. Baš jedna smislena, zdravorazumska hipoteza: S visinom računa raste i manča. Dakle osim što sam konobara pitao koliku manču je taj dan dobio, pitao sam ga i koliki je račun išao uz tu napojnicu. Bilo bi dobro i znati u kojoj smjeni je bolje raditi, ako budem imao izbora da znam pitati da budem jutarnja ili večernja smjena. Ovako intuitivno (neispravno, ali za potrebe blog-primjera će biti u redu), na večer bi trebalo biti više prometa, veći račun - veća manča. Zadnje pitanje koje me muči je isplati li mi se raditi nedjeljom ili ne! Kako ću to ustanoviti? Pa lijepo, usporedit ću prosječnu manču na svaki dan u tjednu i vidjeti mogu li nedjeljom očekivati značajno veću manču - ako da, super, radit ću i nedjelje a ako ne - neću.
Dakle, prikupio sam ukupno 5 varijabli! 1 zavisnu - količinu napojnice (u dolarima) i 4 nezavisne (one za koje očekujem da utječu na moju zavisnu varijablu): ukupan račun (u dolarima), spol konobara, koje doba dana i koji dan u tjednu.
Prosječna količina napojnice koju je konobar dobio je iznosila ravno 3 dolara (sd = 1,38). Što nam ovo znači? To nam znači da znajući ova dva broja (aritmetičku sredinu i standardnu devijaciju, pod uvjetom da se radi o normalno distribuiranoj varijabli) možemo zaključiti da je raspon svih manči u uzorku negdje između 0 (jer nema ispod 0) i 3$(aritmetička sredina) + 3*1,38(standardna devijacija) = 7,14 dolara (ovo 3*sd se odnosi na Gaussovu krivulju, o tome možemo jednom drugom prilikom, to vam je zvono-krivulja s predvidivim svojstvima poput onog da unutar raspona od +/- 1 sd se nalazi 66% uzorka, unutar +/-2 sd 95% uzorka i unutar +/-3 sd se nalazi 99,7% uzorka).

I stvarno, vidimo da se većina vrijednosti nalazi između 0 i 7,5 (ja sam pretpostavio da će to biti 7,14). Ovo je već jedna informacija, no sigurno ne možemo generalizirati na apsolutno sve restorane na svijetu. Zato nam je bitno opisati izmjerene varijable u deskriptivnom dijelu analiza (zato svoje ispitanike ispitujete koju stručnu spremu imaju, koliko su stari, koliko zarađuju i razna druga neugodna pitanja koja neki put niti ne prikažete u analizi). Ja sam npr. provjerio kolika je iznosio proječan račun i dobio da se radilo o 19,79 dolara (sd = 8,90). Opet, ako se radi o normalno distribuiranoj varijabli mogu očekivati da je većina računa negdje između 0 (možda malo više od 0, možda 0,5 $) i 19,79 (aritmetička sredina) + 3*8,90 (standardna devijacija) = 46,49. Pogledajmo što nam život nosi:

Nadam se da je slika jasna, ova zelena površina znači isto što i žuta površina s prethodnog grafa, to je učestalost pojedinog odgovora. Razlika je što su odgovori nacrtani sad na y-osi a ne na x-osi kao na prethodnom primjeru. Isto tako, iako su točkic razmaknute i po x-osi to ne znači ništa nego sam ih ja razmaknuo da nam bude pregledniji graf. Svaka točkica je jedan ispitanika čiji rezultat iščitavamo na y-osi. Vidite i sami da je gustoća točkica najveća gdje je zelena površina najšira.
Isto, kao i gore, dobro sam predvidio (što znači da je varijabla normalno distribuirana) da se uglavno radi i računima oko 20-ak dolara i da za njih mogu očekivati onda 2 dolara napojnice (u prosjeku). E sad kad to sve znam ostaje mi odgovoriti na sljedeća pitanja:
1. Tko dobiva veću napojnicu, muški ili ženski konobari?
Hipoteza: žene dobivaju veću napojnicu
2. Je li bolje raditi jutarnju ili večernju smjenu?
Hipoteza: Napojnice su veće za račune iz večernje smjene.
3. Varira li manča obzirom na dan u tjednu?
Hipoteza: Manča je podjednaka svaki dan u tjednu. (obratite pozornost da za ovo istraživačko pitanje nisam našao utemeljenje u znanstvenoj literaturi već je postavljan intuitivno, stoga, kako bih bio siguran da ne ispadne budala kad kažem da mislim da je utorkom najveća manča, kažem da očekujem da su svaki dan manče podjednake. Vidjet ćete kasnije da takvu hipotezu nazivamo nul-hipoteza odnosno hipoteza da se dvije (ili više) stvari ne razlikuju. Bitna stvar!)
4. Mogu li znati koliku napojnicu ću dobiti unaprijed (znajući koliko račun izdajem)?
Hipoteza: veći račun povezan je s većom napojnicom.
Kad se ovako postave pitanja (na koja bi bilo dobro postaviti i svoje predviđanje koje nazovimo hipoteza) tada je lako dalje. U svakom pitanju nalaze se dvije varijable: zavisna i nezavisna. U sva tri pitanja imamo istu zavisnu - količina napojnice. U prvom imamo spol kao nezavisnu, u drugom doba dana, trećem dan u tjednu i u četvrtom ukupan račun. Budući do sad još nismo radili statističke testove, nećemo ni sad. Grafički ćemo pokušati odgovoriti na postavljena pitanja.
1. Tko dobiva veću napojnicu, muškarci ili žene?

Se sjećate ovih horizontalnih slova H ili intervala pouzdanosti, kad smo pričali o uzorku i populaciji smo pričali da nas ne zanima ništa o uzorku a sve o populaciji a obzirom da su uzorci mali onda se može dogoditi da slučajno uzorkujemo neki mali pristrani dio pa da ne bismo rekli "aha, to je aritmetička populacije" damo si malo "lufta" pa kažemo "da ispitamo još 99 uzoraka jednake veličine, u njih 95 bi se artimetička sredina nalazila unutar ovog našeg intervala pouzdanosti". Gledajući ovaj graf i znajući što predstavljaju ti intervali pouzdanosti i to da se ne preklapaju (niti malo) što možemo reći o razlici u napojnicama kod muškaraca i žena? Pa ja bih rekao da je ta razlika dovoljno velika da bismo je opazili i u populaciji, drugim riječima: da, žene dobivaju veće napojnice.
2. Jutro ili veče?
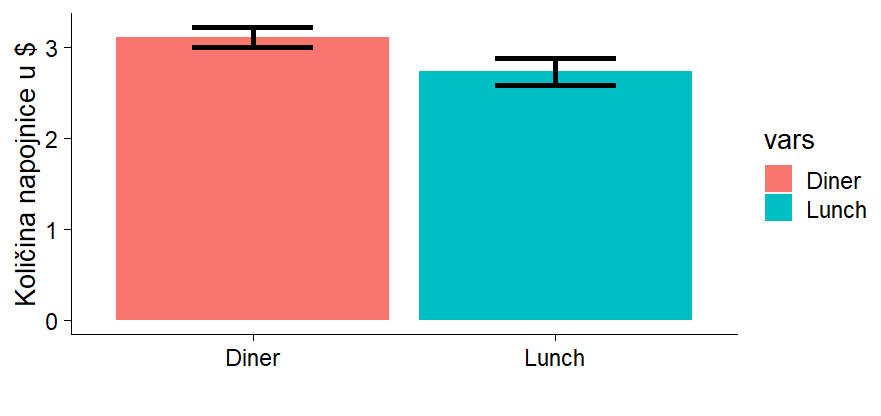
Opet isto, intervali se ne preklapaju, večernja smjena u prosjeku dobije veću manču nego popodnevna/jutarnja. To zaključujem iz činjenice da se intervali unutar kojih se nalazi aritmetička sredina ovog i još 94/99 narednih uzoraka (posebno muških, posebno ženskih) ne preklapaju što mi daje uvjerenje da bi sličan obrazac našao i u populaciji, odnosno da stvarno navečer manče budu obilatije...
3. Raditi ili ne raditi u nedjelju, pitanje je sad.

Opet, neću vam ništa govoriti. Zaključite sami! Kako to sve djeluje komplicirano ali evo, napravili smo analizu varijance (ANOVA-u) i interpretirali je bez ičije pomoći! Bravo svi.. još jedno kratko pitanje pa idemo odmorit zasluženo. Čisto da imate provjeriti jeste li bili u pravu, gledajući u graf rekao bih da nedjeljom i subotom (vikendom, jel) možemo očekivati veću napojnicu u prosjeku nego na radni dan. Kao što sam rekao ovo je primjer jednosmjerne analize varijance (One-Way ANOVA u SPSS-u) i sigurno biste tamo dobili da postoji statistički značajna razlika u napojnici obzirom na dan u tjednu, pa biste dodatnim analizama utvrdili da vikendom je ta manča značajno veća nego radnim danom. No, ono što vam sami brojevi ne bi (tako jasno pokazali) je veličina intervala pouzdanosti od petka. Ako primijećujete on je malo veći od ostalih dana. To može značiti jednu od dvije stvari, ili je petkom bilo svakakvih računa (i jako niskih i jako visokih) ili je najmanje mjerenja napravljeno u petak pa je zato veća nesigurnost gdje se aritmetička sredina točno nalazi.
4. Predvidjeti napojnicu obzirom na račun?

Obzirom na to da još se nismo dotakli korelacije osim da smo rekli da je to sinonim za povezanost, nećemo preduboko ulazit u graf. Pogledajte točkicu u najgornjem desnom uglu, recimo da povučete ravno linije prema lijevo (i očitate cca 10$ napojnice na y osi) i prema dole (i očitate 50$ ukupni račun) a zatim uzmete točku koja je skroz dole lijevo na grafu i očitate da je napojnica cca 1$ a ukupni račun cca 3$ možete primjetiti da što je jedna varijabla (koja god, nebitno jer trenutno pričamo samo o povezanosti a ne o uzročnosti) manja to je i druga varijabla manja, odnosno što je jedna varijabla veća to je i druga varijabla veća. Kad bi ova nacrtana linija bila paralelna s x-osi tada bi svi imali podjednaku napojnicu, bez obzira na račun koji su izdali te bi značilo da ne možemo na temelju računa predvidjeti napojnicu.
Ne želeći vas zbunjivati dodatno, ovdje vas napuštam. Cilj, mada implicitni (evo tek na kraju sam vidio da bi to mogao biti najkorisniji cilj) ovog posta je bio pokazati na praktičnom i jednostavnom primjeru kako bi proces obrade podataka trebao ići i još važnije, kako slika zaista vrijedi tisuću riječi, ali prava slika. Slika pita-grafa koja se rasteže preko 1,5 stranice a pokazuje da je u uzorku bilo 97% žena i 3 % muškaraca, ili još bolje pita-graf koji prikazuje kontinuiranu varijablu... samo smetaju!
Zaključak, u 5 postova došli smo od nule do samostalne provedbe t-test, ANOVA-e i čak regresijske analize (koeficijent korelacije je zapravo regresijska analiza)! Not bad! Zamislite gdje smo za 5 postova!
Do sljedećeg puta!
Nema komentara:
Objavi komentar